Let's Write A Reverb
Geraint LuffNo magic numbers, no tricky tuning: a clean and flexible approach to designing a smooth high-quality reverb, using a variation on the classic feedback-delay network (FDN) structure.
Reverbs are one of my favourite effects, both to use and to write, and feedback-delay networks are a great way to play around and try things.
Reverbs sometimes have a bad reputation for being tricky to tune, so this article goes through one possible reverb design which I hope is simple and intuitive to understand, and I also think is friendly and robust (as in, easy to configure correctly and get a good sound).
So let's get to it!
What do we want from a reverb?
An effect which creates a sense of space, by generating a diffuse longer-lasting sound from a short input
Approaches
There are many ways to achieve this, but two common approaches are convolution and feedback delay networks. There are advantages and disadvantages to both:
Convolution
|
❌ complicated ❌ high CPU ❌ hard to modulate |
✅ very customisable ✅ can imitate real spaces |
We're going to take the FDN approach, because you can make a decent-sounding reverb with low CPU and a fairly simple design.
The feedback-delay loop
Here's a simple feedback loop:
The input signal is sent through a delay, which then goes to the output - but it's also fed back into the delay input. This means the signal travels round in a loop, producing a series of echoes from a single input pulse.
There are a few variations on this, like where in the loop we take the output from, or where the gain is placed. The essential part is the feedback which produces an infinitely-looping output, with a gain to make it decay over time.
A multi-channel feedback loop
Now let's look at a multi-channel version of the same loop:
An important property here is that each channel gets delayed by a different amount, so they each produce a different echo pattern. If we mix all the output channels together, the result still has repeating patterns, but it's more complex than the single-channel version:
Adding a mixing matrix
That more complex sound is good - we don't want identifiable repeating patterns in our reverb. But in the loop above, each channel only repeats its own echoes. Could we get an even more complex result if they picked up each other's echoes as well?
We can achieve this by putting a mixing matrix inside the feedback loop. This is an
Matrices, and orthogonal matrices
If you aren't familiar with matrices, for this article, we can just say: a matrix is a function which takes in multiple inputs, and adds those together in different ways to produce multiple outputs:
A simple example would be a mid-side encoder, which takes two input channels, and returns them in a linear combination:
For a mixing matrix, we treat each simultaneous set of input samples (from the
Orthogonal Matrix
An orthogonal matrix is a matrix where the total energy of the output always equals the total energy of the input.
You don't need to know how to construct these, we're going to use some off-the-shelf orthogonal mixing matrices. However, this property where the output energy matches the input energy is going to be really useful later.
Because of this cross-mixing, as the signal travels around the loop, the echoes appear more and more often, giving an increasingly chaotic result:
The tail end of that is even starting to sound like a reverb, right?
Caution
At this point, it's tempting to mix the channels as much as possible, or put a bunch of other things inside the feedback loop to speed up diffusion.
There are some interesting designs here - and they work, but they often require careful tuning. As well as finding a good compromise for the delay time, using too much inter-channel mixing can lock the delays together so they act like a cohesive unit, which isn't great for longer tails.
Designing a feedback loop to produce a diffuse, long-lasting sound with no strong resonances is hard - but we don't have to do it!
Diffusion
There were two properties we said we wanted from the reverb tail:
- diffuse
Even a basic feedback loop handles the "long-lasting" part nicely. Rather than trying to get the feedback loop to also produce a diffuse sound, we're going to separate the two concerns:
If the diffuser does its job well, we shouldn't really need to build up echo density in the feedback loop.
Now we just need to design a really good diffuser.
Single-channel allpass filters
We want our diffuser to smudge the sound without adding much of its own timbre. A useful concept for this is an allpass filter.
Allpass filters have a flat frequency response (meaning that whatever frequencies you put in, those frequencies have the same energy in the output), but they can have a varying phase response (meaning some frequencies are delayed more than others, providing the "smudging" that we want).
Schroeder allpass
The Schroeder allpass is an IIR filter which often comes up when discussing reverb diffusion. It's made from a (single-channel) feedback loop which produces a series of echoes, with an extra feed-forward part which gives it a flat frequency response:

For a reverb diffuser, the delay-time is typically set to a handlful of milliseconds, so one allpass on its own doesn't provide much diffusion - but you can put a bunch of them in a row. The result is definitely diffuse, but it has a slight metallic edge to it:
More complex designs
You can make more sophisticated allpasses by replacing the inner delay by another allpass, or using second-order allpasses (which can be combined in series to make even higher orders). These can improve the sound by disrupting the very regular phase-response of the basic design.
There are some good designs made from just these basic elements - but choosing a design (or understanding why it's good) isn't very intuitive. It's a tricky tuning problem, from the allpass structures to the delay-times and feedback amounts.
Multi-channel allpasses
Things get a bit more varied if we look at multi-channel allpasses - but first, we need to define what that actually means.
This idea of a flat frequency-response which passes through all frequencies (and minimises colouration for a diffuser) is a good place to start. Let's phrase it slightly differently:
The total energy of the output must match the total energy of the input.
For single-channel allpasses, this is equivalent to the standard "flat frequency-response", but this definition generalises nicely into multi-dimensional/multi-channel situations.
Compared to the single-channel case, we have a slightly wider range of basic building-blocks available. Let's look at a few examples:
Multi-channel delay
Much like a single-channel delay is technically an allpass filter (because it has a flat frequency response), a multi-channel delay fits the bill:
This will be useful for our diffuser: if the input channels are somehow synchronised in time (e.g. an echo occuring in all channels simultaneously), a multi-channel delay can de-sychronise those echoes.
Mixing matrix
Another type of allpass (which only makes sense for the multi-channel case) is a mixing matrix:
Each output channel is a linear combination of the input channels. If some input feature (e.g. an echo at a certain time) appears in only one channel, this distributes that feature across the other channels as well.
The Hadamard family of matrices provides the maximum amount of inter-channel mixing, and can also be computed pretty efficiently for powers of 2 (
Shuffling channels and inverting polarity
OK, so it's not very interesting - but swapping channels around is (technically) a multi-channel allpass. We can also invert the polarity (multiply by
... and more
There are a host of other multi-channel allpass structures available, including:
It's worth noting that in the single-channel case, IIR allpasses are pretty much the only tool we have.
In the multi-channel case, we highlighted some basic building-blocks which don't contain any feedback, but are still enough to design a great diffuser by just combining them in series - which exactly what we're going to do.
A multi-channel diffuser
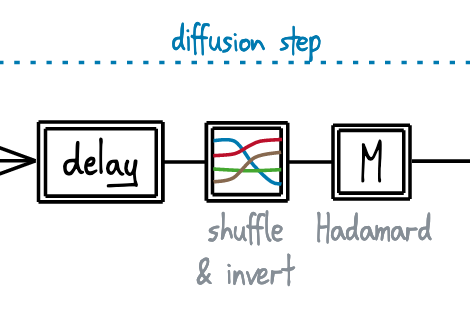
So, here's the plan for our diffuser: we define a "diffusion step", made from a sequence of (multi-channel) operations:
Single diffusion step
The delay takes an input (containing some number of echoes) and un-aligns the channels. After some shuffling, the Hadamard matrix takes each unaligned echo, and redistributes it across all the channels:
Every time we apply a diffusion step like this, we end up with
For a larger number of channels (e.g. 8+), this means we can get a very dense result from a small number of these diffusion steps.
Examples
Let's run some clicks through this diffuser, to see what it sounds like. Here's a 4-channel diffuser, with 3 diffusion steps, each with delays from 0-60ms:
To get smoother diffusion, you can either add more diffusion steps, or increase the number of channels. Here's an 8-channel, 4-step diffuser:
You still need to choose the number of channels and diffusion steps, but it's pretty easy to get a good configuration out of this pattern.
Down-mixing
At some point in our final effect, we need to mix these multi-channel signals back down to a mono (or stereo) output.
When you do this downmixing, the system as a whole stops being an allpass (even if you're just mixing down to the same number of channels as you started with).
This is fine as long as your phase-shifts don't have regular patterns which could produce an identifiable "comb" timbre. The diffuser design we've explored here gives a nicely irregular phase-response, particularly for larger numbers of channels (
Because the Hadamard matrix has mixed things already, we can just take the top 1 or 2 output channels to get a good result - this is what we did for the examples above.
In our final reverb design, the diffuser's multi-channel output will head straight into the multi-channel feedback loop, so we don't downmix until later.
Choosing delay times
Once you've decided what range of delay times you want for a particular diffusion step, you could pick each channel's delay time randomly. However, if you divide the range into equal segments, and use one sub-range for each channel, they end up approximately evenly-distributed while still being randomised.
Uneven diffusion steps
There's no reason the diffusion steps need to have similar delay-lengths. You could stack together short steps and long steps.
To show the difference, here's a really long diffuser: 8 channels, 5 diffusion steps, with delays from 0-300ms:
Here's a similar setup with the same total diffusion length, except each diffusion step is twice as long as the last:
This gives a smoother start/end, and a less noticeable "peak" in the middle.

So, it's not like you can't experiment and tweak this design - but both of the options sound pretty good. Varying the diffusion-step sizes like this just puts a bit of icing on the cake.
Putting it together
So: we have a multi-channel diffuser, and we have a multi-channel feedback-delay loop. All we have to do is duplicate our input, and mix down our output, and we're done!
Here's our combined design:
The input and output don't have to be mono - just choose something appropriate when converting to/from
Examples
We'll use a fairly long reverb configuration:
- 8 channels for the diffuser and feedback-loop
- 4 diffusion steps (20ms, 40ms, 80ms, 160ms)
- feedback gain of 85%
- feedback delays from 100-200ms
Click response
Here's what happens when we put a short "click" through it:
Pretty smooth! Let's try it on some more musical inputs:
Drums
Here's a little drum riff:
And here's the output from our reverb:
Piano
Here's a little bit of piano:
And here's the output from our reverb:
Next steps
This is a very minimal reverb design, and there are loads of ways to extend it. I'm not going to go into much detail, just sketch out a few things you might want to add:
Early reflections
The delays in the feedback loop mean there's a gap between the original sound and the earliest echoes. To bridge this gap, we can use a separate delay path (taken from the diffused signal) to fill the time until the first echoes from the feedback loop come through.
The diffuser itself also delays the sound a bit - so we could even take some input from earlier in the diffuser, so the reverberation starts as sharply as possible (especially if the earlier diffusion steps have shorter delays as mentioned above).
Modulation
In a real space, small movements in the environment (even air currents) produce subtle variations in delay times. In an FDN reverb, this can be modeled by gently modulating some of the delay times - or cranked way past realism to get a supernaturally thick sound.
There are a couple of places where you could modulate the delays in this design, which will produce slightly different sounds:
Filtering
In real spaces, high frequencies are often absorbed faster, and have shorter decay times. We can achieve this in an FDN reverb by using shelving filters to get frequency-dependent decay gain.
With those extra details in the design, you can get some a pretty good sounds:
That's it!
Hopefully it wasn't too complicated. You can look at some C++ example code to see these ideas in action.
I really wanted to write this article, because many of the better-known FDN designs include magic numbers or peculiar allpass structures which seem like they've been very carefuly tuned.
I didn't like this, and when one day someone asked me to write "a reverb" (no specifics), I sketched out a design which included no IIR allpasses, and was robust enough that I could throw a random-number generator at all the delay times and it would still sound good.
This is a distilled version of that design, and I hope it's a useful starting point from which people can try a bunch of interesting things. 🙂