Constant-time peak-hold
Geraint LuffSignalsmith Audio Ltd.
Looking at some ways to implement peak-hold (sliding maximum), including one with constant O(1) complexity.
Peak-hold
There are a couple of places in audio where we want to know the maximum value of a moving window.

The most straightforward way to calculate this would be to keep all the recent history we need in a buffer. When we need to get the maximum value, we just loop through the recent history to get it:
This would be slow, because you have to loop through that range every sample - and takes more work the longer our period is.
Two stacks
Fortunately, there's a fairly well-known solution to this, which takes O(1) time... on average. The key is to split the region into two sections, which we'll call "front" and "back":
If we have a maximum value for both regions, the result we need is just the maximum of those two.
Adding samples to the front
To add new samples to the front and get an updated front-maximum, you just take the maximum of the previous front-region and the new samples.
Removing samples from the back
This is a bit more fiddly, because we can't really calculate it on-the-fly. What we want is a sequence of overlapping maximum ranges, and when we drop a sample we just move onto the next one:
Calculating these maximums individually would be slow - but calculating them all at once is pretty efficient, since we can do a cumulative maximum in reverse. But when do we calculate this?
Moving the boundary
At some point if we keep popping samples off the back, the back region is going to end up empty:
At this point, we move the boundary - this is also the moment when we calculate our reverse-cumulative-max sequence for the back region.
Implementation
Here's some example C++ code:
If you know the maximum total length of your window, your front and back buffers could share the same buffer:
Additionally, if you wanted to be able to push samples onto the back or pop them from the front, you'd need to store a rolling maximum for the front half, and samples for the back half. The code above only lets us move the window forwards.
Computational cost
In terms of complexity, this is O(1) - but only on average. Most updates are very cheap, but every backSequence is empty), .popBack() has to iterate through all frontSamples, as we construct the reverse-cumulative-max for the new back region.
Run-length encoding
There are a few alternatives with similar properties. I'm not going to examine it in as much detail, but one of my favourites essentially maintains a run-length-encoded future output:
When we get a new input sample, we erase any parts of this future output which would be below this:
This also has O(1) average complexity, but rather than having a predictable spike in computation every
This run-length approach was what I used until recently, when I came across...
Constant-time peak-hold
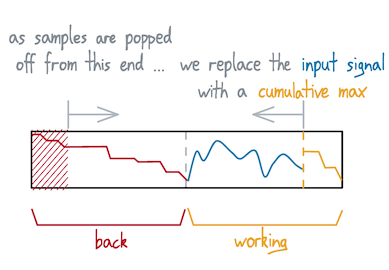
This scheme is a variation of the two-stacks method. Instead of splitting into two parts, we split into three:
An essential property is that this "working" region needs to be half the total length. At the moment when our back region is empty and we swap the regions over:
... the working is the same length as the back region. We use this to avoid calculating our reverse-cumulative-max all at once, and instead calculate it gradually at the same time as we consume the back region.
Here's an animation of what that might look like:
Advantages
We no longer have a big (length-dependent!) computational spike when we swap the regions over. This means our algorithm is consistently O(1), instead of on average, which is good for real-time system.
Disadvantages
Because the working region has to be the same length as the back region in order to spread the calculations out evenly, changing the length is tricky. We also have to be a little careful with odd-sized lengths.
Variable sizes
For my implementation, I wanted to still support unbalanced push/pop to change lengths, so I put in extra checks when swapping regions:
- If the middle section is longer than the back section, push half of the surplus back into the front. Then, recalculate the front's maximum, and enough of the middle's reverse-cumulative-sum for it to finish on time.
- If the new back section is empty, swap again. If the back section is still empty, you've popped from an empty list, so fail gracefully.
- Some extra checks to support size 0
Even though you sometimes have to do a bigger chunk of work, it remains average-O(1) - as well as being constant-O(1) complexity in the constant-size case. I'm pretty happy with this. 🙂
Why is this interesting?
While any opportunity for an animated graph is enough to justify a blog-post 😛, I've used peak-hold envelope followers recently when writing a limiter - which I've now written up as its own article.
But in particular, the constant-O(1) approach is good for real-time audio effects, where you don't really want sudden bursts of calculation in your real-time audio effect if you can avoid it. This is now the implementation I use in my DSP library.